Edit thinking about this I myself would not look at a link, posted by an unknown person, to code so I have deleted the file have emoved the link. I will post screen captures of the code instead
Please bear with me as I give a bit of back ground.
This relies completely on TXTlogToCSVtool.exe and TXTlogToCSVtoolMM.exe and running those programmes on the appropriate DJIFlightRecord_yyyy-mm-dd_[hh-mm-ss].txt logs that have been downloads from the screen devices to a PC running windows.
see the opening post in [TOOL][WIN] Offline TXT FlightRecord to CSV Converter
I can't remember if TXTlogToCSVtool.exe etc. can only run on a Windows machine but it is where I run it, via the command line. I open the command line window in the folder that holds the flightlogs, this avoids having to figure out the "path" to the flightlog's folder.
For the Go and Go4 App .txt flightlogs I, type and enter in that command line window,
FORFILES /m *.txt /C "TXTlogToCSVtool /c @file @fname.csv" .
For the FLY (pre 1.2....) I type and enter
FORFILES /m *.txt /C "TXTlogToCSVtoolMM /c @file @fname.csv" .
The result is the processing of all the .txt files in that folder so make sure there are no non flightlogs in there.
The output are .csv's with the same name as the orignal flight logs. The original .txt flightlogs remain.
The csv's contain various bits of information which are stored in specific columns, which column depends on what that information relates to. It seems that Go, Go4 and FLY use the same columns for the same information thus, for example, column 235 is the drones' activation date and time.
Next is where an easy solution comes unstuck.
Those .csv's require further processing to extract the information desired and I can not DOS program, I am hopeless at it.
If I try to follow manuals etc. it's as if I were trying to translate a Vulcan literary masterpiece using a Narn translation of a Wraith dictionary (and yes mixing up my Scifi series was deliberate as it adds to the confusion.) I refer to "DOS" rather than searching for the modern name to reflect my inabilities in 'DOS'.
I am more familiar with the Linux 'programming languages AWK GAWK so I have to switch to a Linux machine.
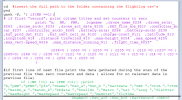
The result is given below. I couldnt attach the txt containing the code so was advised to post it here
link removed
An crude explanation of the programme, it can stored as a file without an extension but the file has to be made "executable". I think this is similar to windows and the use of batchfiles.
Lines starting "#" are comments and not treated ae programming commands
"cd #insert the full path to............" switches to the folder containing the csv's to be processed. Mine are on an external HDD, so for me it is something like
cd /media/sean/external_HDD/flightlog_csv-s .
Putting them somewhere in windows drive C might complicate things a bit. You would need to change "#insert the ful......." to whatever is relevant to your storage location.
"gawk" I think it tells the computer to use the GAWK language.
gawk reads the files one at a time and in so doing splits a file into its lines, "records". It also splits each line into chunks, "fields". What determines the boundary between the field can be set by the user.
The "-F," bit tells gawk to use a comma, as in , as the field separator/boundary.
Regarding the " '{ " bit, I am not sure precisely what they do but they are necessary and so are their opposites at the other end of the program i.e. }'
A bit about line counting in gawk, gawk counts at least two things in connection with lines from input files
1) the total number of input lines it has processed so far, it stores this count under the name NR.
2) the number of input lines that it has processed so far FROM THE CURRENT FILE BEING READ, it stores this count under the name FNR
Both NR and FNR increment with each line. FNR is reset to something (possibly 1) when the program start to read a new file but is equal to 1 by the time the first line is being read.
The first if statement (in purple if the colouring survives) prints what will be the column titles for the output e.g.drone_name_$234 etc. and sets a number of counters e.g. c234 to zero. "234" etc. refers to the column number (just my way of identifying the column). It is executed once and only once.
With regard to "if(NR==1){ ......}" the NR==1 is the test that stops the title being printed every time reading of a new file starts because ..... in English it amounts to "if and only if NR equals 1, do, whatever is inside the { }".
The next if statement, in green???, is a bit of a "what comes first, the chicken or the egg?" thing.
It reads as "if NR is NOT equal to 1 and if FNR (the file line count) IS EQUAL to 1 then, do whatever is inside the following { }" which is, {output the data gathered in the pass through the previous file}. There probably is a better way to code this but I do not know how. The program does not know anything about any file until it has read that file and has to output the data "after the event", this is my way of dealing with that. The counters and storages are zeroed because if the current file has no data for any given column the values gathered during the scan of the previous file would be carried through into the scanning of the current file and not reset, thus the apparent data for the current file is actually the data from the previous file.
The remaining group of if statements, in pink????, search each line for the desired data and store it under an appropriate name, when suitable data is found the counter for that sort of data i.e. a specific column, increments to 1 and prevents future searches in that column in that file.
If I wanted only data that had a fixed value whereever it occurred within any given file, it would, I think, be possible to used 2nd counter in each of the 'grouped' ifs to count how many of the running searches had been satisfied. Once they had all been satisfied the program could be forced to skip the remainder of the file and start on the next file.
HOWEVER as far as I can see the 'maximum distance from the home point' i.e. "maxDist=$11" does not have a column that lists the ultimate maximum distance, thus the whole file needs to be scanned to ensure the final value is correct. This column is probably the biggest time eating column.
"FILENAME" is where gawk stores the name of the current file being scanned. pNR, pFNR and pfn merely carry the values of NR, FNR and FILENAME for the current file through to the green? if statement at the start of the next file.
Regarding "} '" at the end of the program, in my language this marks the aft end of the gawk program and is necessary.
The "*.csv " tells the gawk program to scan every .csv in the current directory/folder and the
" > a_subfolder/logbook_name.csv"
tells the program to put its out put in the file "logbook_name.csv" which is in the folder/directory "subfolder".
This is free for anyone that wants to use it and can. Mac users might be able to use it.
You can adjust it to suit your wants by adding or removing or changing the sought columns but be sure to MOST CAREFULLY follow through with changing the print statements and the grouped if statements.
In truth I am hoping a 'DOS' programmer will see this and create a 'DOS' version and add it to this thread. If 'DOS' offers similar capabilities to gawk then I think this would be a fairly simple bit of coding for a batch file.
For reference, I scanned 1900+ logs and the final NR was near 3,000,000.
It took 2min 18sec.
Please bear with me as I give a bit of back ground.
This relies completely on TXTlogToCSVtool.exe and TXTlogToCSVtoolMM.exe and running those programmes on the appropriate DJIFlightRecord_yyyy-mm-dd_[hh-mm-ss].txt logs that have been downloads from the screen devices to a PC running windows.
see the opening post in [TOOL][WIN] Offline TXT FlightRecord to CSV Converter
I can't remember if TXTlogToCSVtool.exe etc. can only run on a Windows machine but it is where I run it, via the command line. I open the command line window in the folder that holds the flightlogs, this avoids having to figure out the "path" to the flightlog's folder.
For the Go and Go4 App .txt flightlogs I, type and enter in that command line window,
FORFILES /m *.txt /C "TXTlogToCSVtool /c @file @fname.csv" .
For the FLY (pre 1.2....) I type and enter
FORFILES /m *.txt /C "TXTlogToCSVtoolMM /c @file @fname.csv" .
The result is the processing of all the .txt files in that folder so make sure there are no non flightlogs in there.
The output are .csv's with the same name as the orignal flight logs. The original .txt flightlogs remain.
The csv's contain various bits of information which are stored in specific columns, which column depends on what that information relates to. It seems that Go, Go4 and FLY use the same columns for the same information thus, for example, column 235 is the drones' activation date and time.
Next is where an easy solution comes unstuck.
Those .csv's require further processing to extract the information desired and I can not DOS program, I am hopeless at it.
If I try to follow manuals etc. it's as if I were trying to translate a Vulcan literary masterpiece using a Narn translation of a Wraith dictionary (and yes mixing up my Scifi series was deliberate as it adds to the confusion.) I refer to "DOS" rather than searching for the modern name to reflect my inabilities in 'DOS'.
I am more familiar with the Linux 'programming languages AWK GAWK so I have to switch to a Linux machine.
The result is given below. I couldnt attach the txt containing the code so was advised to post it here
link removed
An crude explanation of the programme, it can stored as a file without an extension but the file has to be made "executable". I think this is similar to windows and the use of batchfiles.
Lines starting "#" are comments and not treated ae programming commands
"cd #insert the full path to............" switches to the folder containing the csv's to be processed. Mine are on an external HDD, so for me it is something like
cd /media/sean/external_HDD/flightlog_csv-s .
Putting them somewhere in windows drive C might complicate things a bit. You would need to change "#insert the ful......." to whatever is relevant to your storage location.
"gawk" I think it tells the computer to use the GAWK language.
gawk reads the files one at a time and in so doing splits a file into its lines, "records". It also splits each line into chunks, "fields". What determines the boundary between the field can be set by the user.
The "-F," bit tells gawk to use a comma, as in , as the field separator/boundary.
Regarding the " '{ " bit, I am not sure precisely what they do but they are necessary and so are their opposites at the other end of the program i.e. }'
A bit about line counting in gawk, gawk counts at least two things in connection with lines from input files
1) the total number of input lines it has processed so far, it stores this count under the name NR.
2) the number of input lines that it has processed so far FROM THE CURRENT FILE BEING READ, it stores this count under the name FNR
Both NR and FNR increment with each line. FNR is reset to something (possibly 1) when the program start to read a new file but is equal to 1 by the time the first line is being read.
The first if statement (in purple if the colouring survives) prints what will be the column titles for the output e.g.drone_name_$234 etc. and sets a number of counters e.g. c234 to zero. "234" etc. refers to the column number (just my way of identifying the column). It is executed once and only once.
With regard to "if(NR==1){ ......}" the NR==1 is the test that stops the title being printed every time reading of a new file starts because ..... in English it amounts to "if and only if NR equals 1, do, whatever is inside the { }".
The next if statement, in green???, is a bit of a "what comes first, the chicken or the egg?" thing.
It reads as "if NR is NOT equal to 1 and if FNR (the file line count) IS EQUAL to 1 then, do whatever is inside the following { }" which is, {output the data gathered in the pass through the previous file}. There probably is a better way to code this but I do not know how. The program does not know anything about any file until it has read that file and has to output the data "after the event", this is my way of dealing with that. The counters and storages are zeroed because if the current file has no data for any given column the values gathered during the scan of the previous file would be carried through into the scanning of the current file and not reset, thus the apparent data for the current file is actually the data from the previous file.
The remaining group of if statements, in pink????, search each line for the desired data and store it under an appropriate name, when suitable data is found the counter for that sort of data i.e. a specific column, increments to 1 and prevents future searches in that column in that file.
If I wanted only data that had a fixed value whereever it occurred within any given file, it would, I think, be possible to used 2nd counter in each of the 'grouped' ifs to count how many of the running searches had been satisfied. Once they had all been satisfied the program could be forced to skip the remainder of the file and start on the next file.
HOWEVER as far as I can see the 'maximum distance from the home point' i.e. "maxDist=$11" does not have a column that lists the ultimate maximum distance, thus the whole file needs to be scanned to ensure the final value is correct. This column is probably the biggest time eating column.
"FILENAME" is where gawk stores the name of the current file being scanned. pNR, pFNR and pfn merely carry the values of NR, FNR and FILENAME for the current file through to the green? if statement at the start of the next file.
Regarding "} '" at the end of the program, in my language this marks the aft end of the gawk program and is necessary.
The "*.csv " tells the gawk program to scan every .csv in the current directory/folder and the
" > a_subfolder/logbook_name.csv"
tells the program to put its out put in the file "logbook_name.csv" which is in the folder/directory "subfolder".
This is free for anyone that wants to use it and can. Mac users might be able to use it.
You can adjust it to suit your wants by adding or removing or changing the sought columns but be sure to MOST CAREFULLY follow through with changing the print statements and the grouped if statements.
In truth I am hoping a 'DOS' programmer will see this and create a 'DOS' version and add it to this thread. If 'DOS' offers similar capabilities to gawk then I think this would be a fairly simple bit of coding for a batch file.
For reference, I scanned 1900+ logs and the final NR was near 3,000,000.
It took 2min 18sec.
Last edited: